L'utilisation des outils
statistiques n'a globalement pas
été satisfaisante pour notre controverse et cela
ne nous permet évidemment pas
de présenter de carte lisible et exploitable pouvant
éclairer la controverse et
sa dynamique. Toutefois, il est possible, grâce à
une approche méthodologique
rigoureuse des outils proposés, notamment du Web of
Science, de tenter de
tirer des conclusions intéressantes de cet échec,
c'est à dire du fait que la structure
des données Web sur le sujet est peu compatible avec
l'utilisation de ces outils.
WEB OF SCIENCE :
Le
principe vu par le statisticien :
L'intérêt majeur de l'utilisation du Web
of Science est qu'il cible précisément la
composante scientifique de la
controverse; en effet, à partir d'une large base de
données de publications
scientifiques et techniques on peut effectuer des recherches
très fines
concernant un sujet précis. Par ailleurs, si les articles
eux-mêmes sont bien
sûrs répertoriés ainsi que leurs
résumés (voire parfois l'ensemble de leur
contenu), les jeux de citations entre eux sont également
fournis. Combien de
fois un article donné a-t-il été
cité? Par qui? Qui l'auteur cite-t-il? Le
traitement de l'ensemble des articles trouvés autour d'un
sujet permet donc de
trouver les interconnexions entre auteurs et de les illustrer
graphiquement
grâce à certains logiciels
spécialisés, comme Pajek. Moyennant certains
algorithmes de traitement, on peut établir un lien direct
entre proximité
géographique et proximité intellectuelle et
ainsi dégager les grands groupes
d'acteurs ainsi que les théories adverses sur le sujet.
Approche
de notre sujet :
La démarche logique
semblait être, en tout premier lieu, de
faire la recherche la plus générale possible,
avec pour simple mot-clef « bluefin
tuna », appellation anglaise du thon rouge.
Bien entendu, la quantité
de résultats obtenus a été
considérable (505 articles exactement). Nous avons
toutefois tenté de réaliser une
première approche du problème en
réalisant une
cartographie de l'ensemble des articles trouvés. Nous voulions ensuite
identifier et isoler une
zone bien précise qui aurait correspondu à notre
sujet (grâce aux noms déjà
obtenus par les journalistes par exemple), et ainsi situer le
problème nous
intéressant dans un contexte très global. Mais la
quantité et la complexité de
l'ensemble des données n'ont malheureusement pas
été traitables par les
ordinateurs que nous avions à disposition, qui ont
rapidement saturé.
Nous avons donc naturellement
sélectionné et ciblé les
données qui nous intéressaient plus
particulièrement dans tous les articles
concernant le thon rouge, en regroupant ceux faisant intevenir les
termes quotas,
quota, endangered, threatened, threaten, fishery, farming et
autres termes
proches, pour aboutir à la quantité encore
importante d'une centaine
d'articles. Cette fois le traitement a fonctionné mais,
étant donné le grand
nombre d'auteurs, la carte n'était toujours pas lisible (cf
doc1). Ce qui nous
a inquiétés est que le passage à
l'algorithme de Fruchterman Reingold, qui
rapproche les auteurs par proximité intellectuelle, n'a rien
donné non plus. Et,
en zoomant, on se rend compte qu'il n'y a aucun lien entre les auteurs.
En
remontant aux articles eux-mêmes, nous nous sommes rendus
compte que les
citations étaient toujours d'un nombre extrêmement
faible, et que lorsqu'elles
n'étaient pas purement et simplement inexistantes, il
s'agissait en fait la
plupart du temps d'auteurs ayant publié plusieurs articles
et se citant
eux-mêmes. Nous avons toutefois tenté d'autres
approches avant d'arriver à une
conclusion catégorique.
Nous avons en effet
travaillé sur des ensembles thématiques
plus restreints, quitte à perdre en information, pour
connaître chaque article
plus en détail en lisant chaque
résumé, puis élargir,
compléter par de nouveaux
articles, en effectuant le même type de recherche approfondie
au sein des
publications des auteurs dont le nom revient souvent. Nous pensions
ainsi
trouver des ensembles plus localisés, avec des
interconnexions exploitables.
Malheureusement, cette nouvelle méthode n'a pas non plus
fonctionné (cf doc 2).
Le seul résultat
avec lequel nous avons trouvé quelques interconnexions
concerne un groupe de chercheurs japonais, dont le centre est le
professeur Y. Matsuda, affilié
à la Kagoshima University,
au Japon. Il a émis une théorie originale selon
laquelle le rythme actuel de
pêche ne menace pas directement le thon rouge, défendant par ailleurs l'idée que les
modèles actuellement
utilisés doivent intégrer une inertie
de la masse des thons rouges
beaucoup plus importante que celle habituellement utilisée.
Mais les
interconnexions n'étaient cette fois encore pas
satisfaisantes et nous nous
sommes rapidement rendus compte, après quelques recherches,
que les acteurs
identifiés ne correspondaient guère
qu'à une équipe de recherche au sens
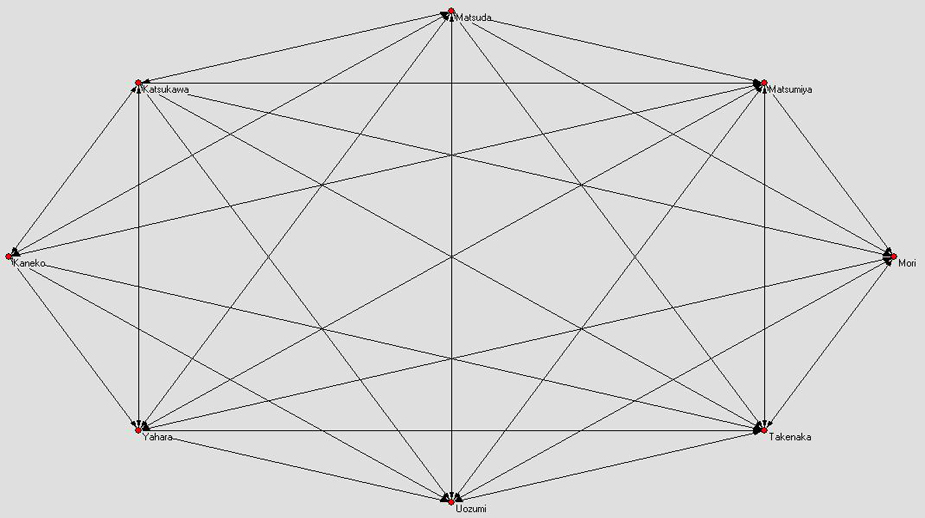
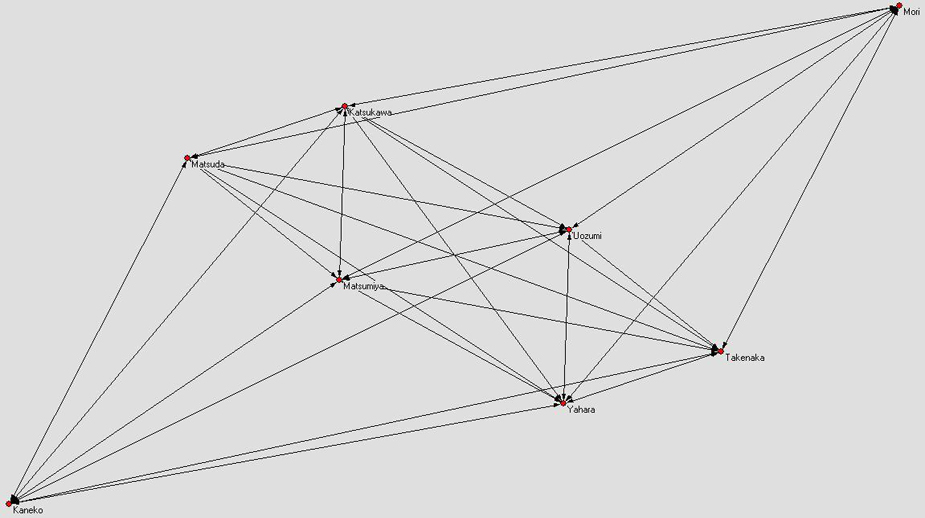
élargi, autour du professeur Matsuda (cf doc3a et doc3b
(traité en Fruchterman
Reingold 2D, où le noyau de l'équipe de recherche
est l'hexagone central)). Ces
échecs nous ont au moins permis d'identifier
plusieurs théories
totalement différentes au sein de la communauté
scientifique, et l'équipe de
recherche de Matsuda se démarquait nettement de la plupart
des autres, beaucoup
plus alarmistes en général. Nous avons
également noté que les divergences
majeures entre scientifiques se situaient au niveau de la
modélisation et des
méthodes d'évaluation des masses
thonières.
Quelles conclusions tirer de
ces difficultés rencontrées ?
Les chercheurs publiant sur ce
sujet travaillent
manifestement de façon extrêmement
indépendante, sans qu'il y ait de
communication entre eux. Cela ne signifie pas qu'il n'y a pas
controverse,
puisqu'il existe des théories quasiment opposées
sur le sujet; la dynamique de
la controverse dans toute sa complexité, les
débats et échanges directs se
situent simplement à un autre niveau, notamment politique,
et les scientifiques
arrivent en bout de chaîne pour élaborer ou
appuyer les différentes théories
existantes.
ISSUE CRAWLER
Le principe vu par
le statisticien : L'IssueCrawler permet, à partir
de quelques adresses Web
rentrées par l'utilisateur, de
« ratisser » le Web en explorant
les
liens successifs rencontrés et d'établir une
véritable cartographie Internet
de la controverse.
Traitement de notre
sujet : Nos premières tentatives de Crawl
utilisaient uniquement des
adresses de sites techniques comme Google Scholar ou le Web of Science.
Mais
comme lors de notre précédente expérience, ceci n'a pas abouti. Les tentatives
suivantes ont donc utilisé principalement des pages de liens
de sites
gouvernementaux et d'ONG comme Greenpeace ou WWF. Là aussi, nous nous sommes vus renvoyés au bout quelques
jours un message d'erreur nous signalant l'échec du Crawl. L'interprétation
de cet événement est ici
beaucoup moins aisée que dans le cas du Web of Science,
puisque nous ne maîtrisons
quasiment rien du processus technique qui aboutit, dans les cas
favorables, à
une carte utilisable.