
Même s’ils ambitionnent de prédire la criminalité, les algorithmes de police prédictive ne peuvent pas prévoir le futur et empêcher des crimes spécifiques. Ils peuvent seulement utiliser les données à leur disposition et s’appuyer sur des principes criminologiques mathématisés pour indiquer les zones ou les personnes possédant les plus hauts risques de criminalité. Cependant la validation de ces algorithmes, tant au niveau du modèle utilisé que de leur application, reste débattue.
Les algorithmes de prédiction s’appuient sur différents concepts criminologiques préexistants. Pour que la notion même de prédiction ait un sens, il faut supposer que les crimes ne sont pas totalement aléatoires et que leur survenue possède une certaine régularité statistique. Cette hypothèse est justifiée par la notion de répétition de la victimisation. Dans les années 80, le criminologue Ken Pease a remarqué que « la plupart des cambriolages se répète sur un petit nombre de victimes » (Benbouzid, 2015) . Il est donc possible d’identifier les zones les plus à risque en se basant sur la donnée des crimes passés. C’est la théorie des hot spots. La police prédictive consiste alors, toujours selon les travaux de Pease (cité par Benbouzid, 2015), à tenir compte de la contagion des zones à haute criminalité vers les autres zones. Xavier Raufer, essayiste et directeur des études au Département des recherches sur les menaces criminelles contemporaines à l’université de Paris II, affirme au contraire que les délits passés ne suffisent pas à prédire les crimes futurs (Raufer, 2015). Dans les domaines de la prévision des séismes ou de l’évaluation des subprimes, les algorithmes se sont en effet déjà révélés inefficaces, affirme-t-il.
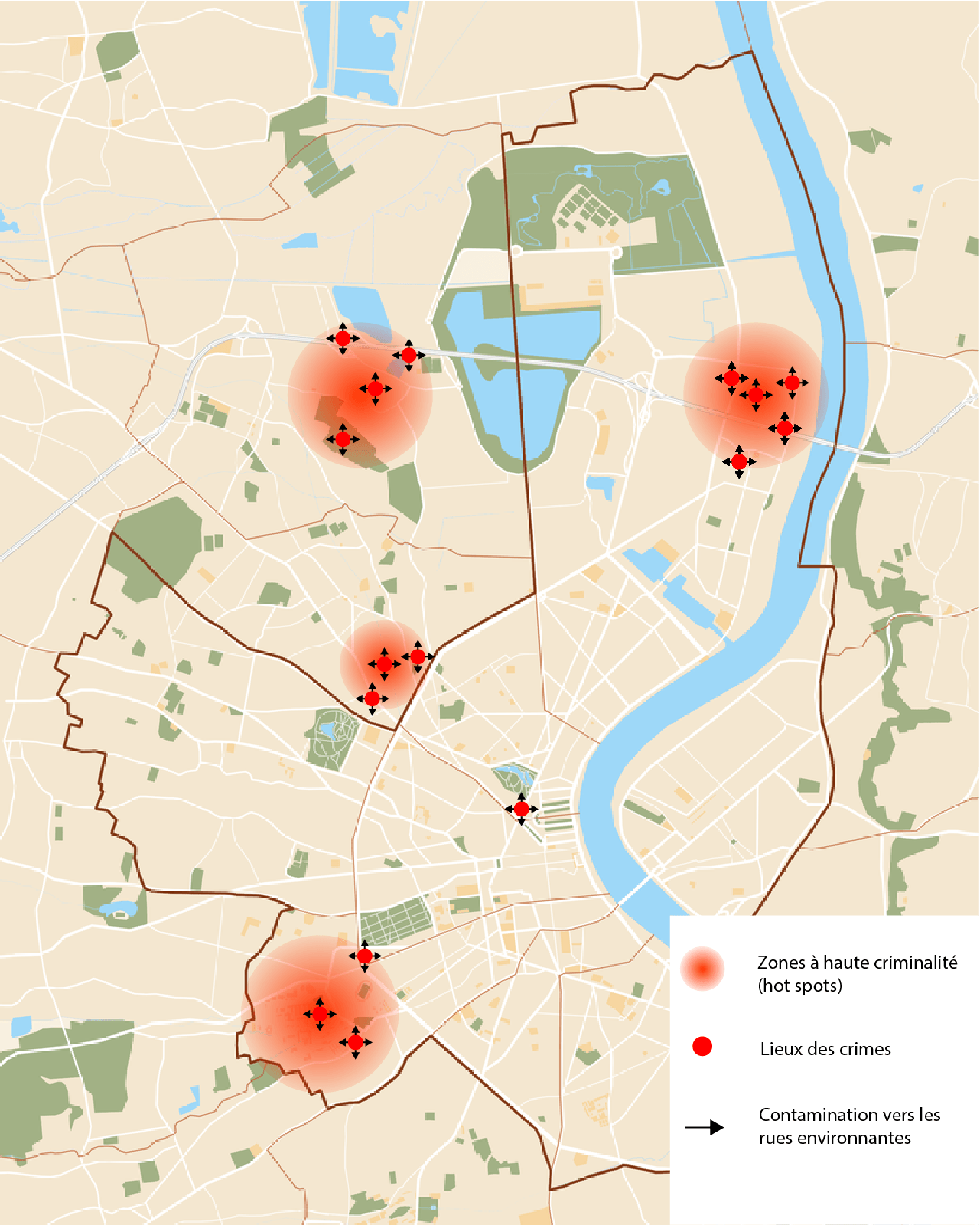
La police prédictive s’inscrit dans l’approche de la prévention situationnelle. Bilel Benbouzid, sociologue à l’université de Paris Est, définit son postulat de base par l’idée « qu’il est plus opportun de s’intéresser à l’événement (la situation du passage à l’acte du délinquant) qu’aux phénomènes de criminalité (les conditions sociales de son apparition)» (Benbouzid, 2010). Le criminologue et sociologue Tim Hope (cité par Benbouzid, 2015) conteste cette approche, en promouvant une approche plus sociale de la sécurité, qui est pour lui un bien de club, c’est-à-dire que la sécurité s’organise comme un bien mutualisé dans une communauté, mais dont les personnes extérieures sont exclues.
Pour prédire les crimes, certaines approches conduisent à utiliser d’autres indices de criminalité que les crimes passés. Le criminologue Matthew Williams et ses collaborateurs, membres du Data Innovation Research Institute, s’appuient par exemple sur la théorie de la vitre brisée (Williams, Burnap, & Sloan, 2016) : la détérioration de l’environnement urbain attirerait les actes criminels.
L’implantation des algorithmes repose sur de nombreux choix de conception. Lyria Benett Moses et Janet Chan, du UNSW Australia and Data to Decisions Cooperative Research Centre à Sydney, détaillent les nombreuses hypothèses sous-tendant l’utilisation de la police prédictive (Moses & Chan, 2016). Il faut d’abord supposer que les crimes passés reflètent les crimes futurs. Ensuite il faut choisir un modèle permettant de mathématiser les principes criminologiques. Predpol utilise par exemple un algorithme initialement utilisé pour prédire les répliques de tremblements de terre (Mohler, Short, Brantingham, Schoenberg, & Tita, 2011). Mais de nombreuses autres techniques sont possibles et chacune a ses limites. Les algorithmes ne peuvent par ailleurs utiliser qu’un nombre limité de variables et il faut supposer que les variables omises ne sont pas pertinentes. Aaron Shapiro, doctorant en "critical urban studies and media studies" à l’université de Pennsylvanie, critique par exemple Predpol qui n’utilise que trois variables (le type de crime, le lieu et la date) et dont le modèle pourrait donc être trop simple (Shapiro, 2017).
Moses et Chan pointent également l’importance que les données utilisées reflètent correctement la réalité. Les données peuvent être de nature diverse : la majorité des algorithmes se concentrent sur les fichiers de crimes déclarés à la police mais certains sont censés utiliser les réseaux sociaux, notamment Twitter pour analyser les détériorations de l’environnement (Williams et al., 2016). Cependant, des associations comme l’Union Américaine pour les Libertés Civiques alertent sur le biais des données utilisées (Edwards, 2016). Les fichiers de la police américaine seraient en effet biaisés par le racisme, ce qui met en doute la fiabilité et l’impartialité des prédictions. Les algorithmes se concentreraient alors sur certaines minorités, qui seraient davantage interpellées, renforçant encore le biais des données dans un cercle vicieux de racisme.
Pour évaluer la confiance que l’on peut accorder aux prédictions des algorithmes, il faudrait connaître leurs hypothèses de fonctionnement et la façon dont les algorithmes sont implantés. Xavier Raufer pense d’ailleurs que les algorithmes peuvent avoir été « truqués » de façon volontaire ou non (Raufer, 2015). De nombreux acteurs plaident donc pour la transparence totale. Bilel Benbouzid critique fortement Predpol pour l’opacité qu’il entretient autour de son algorithme, qualifié de « boîte noire ». Dans son article de Mediapart, le journaliste Jérôme Hourdeaux met en évidence l’inquiétude suscitée par le secret autour de ces thématiques (Hourdeaux, 2015). Édouard Geffray, le secrétaire général de la Commission nationale de l’informatique et des libertés (Cnil), qu’il cite, montre que la Cnil ne dispose pas des moyens de contrôler les algorithmes. Pete Burnap, professeur associé en sociologie et cybersécurité à l'université de Cardiff, souhaite aussi avoir accès au code des algorithmes prédictifs (Cortes, 2016). Selon lui, ils ne devraient pas être de simples outils de répression pour la police mais des outils de compréhension du crime et de son origine pour les sociologues. Cependant, les entreprises de police prédictive comme Predpol refusent d’ouvrir leur code, afin de protéger le secret professionnel de leurs algorithmes.
Lors de l’évaluation des résultats des algorithmes, il faut distinguer, selon Perry et al., qui ont rédigé un rapport sur la police prédictive pour la RAND Corporation (Perry, McInnis, Price, Smith, & Hollywood, 2013), leur efficacité à prédire les crimes et leur utilité à long terme sur la réduction de la criminalité.
Comme Predpol est le logiciel de police prédictive le plus connu, plusieurs travaux ont tâché de déterminer sa capacité à prédire les crimes : ses prédictions sont-elles en accord avec la réalité du terrain ? À partir des mêmes données du crime à Chicago, le sociologue Ismaël Benslimane a procédé à une comparaison entre les résultats de George Mohler (2014), le chercheur à l’origine de l’algorithme utilisé par Predpol, et ceux obtenus par une simple méthode de hot spots. Les deux méthodes aboutissent au même score d'efficacité (Benslimane, 2014). De plus, il critique la communication de Predpol sur son efficacité : le manque de rigueur statistique permettrait à Predpol de promettre une efficacité plus grande que la réalité. Bilel Benbouzid a par ailleurs contacté David Marsan, le sismologue à l’origine du modèle de prédiction des répliques de séismes sur lequel repose Predpol (Benbouzid, 2016). Il lui a demandé de refaire les calculs grâce à son modèle, à l’aide des données de cambriolage du FBI. Le sismologue conclue que son modèle (et probablement celui de Predpol, dont le code n'est pas accessible) n’est pas statistiquement meilleur qu’un algorithme de hot spots (Marsan, 2016). La contagion est donc négligeable. Marsan pointe aussi que la dynamique du processus de criminalité pourrait varier au cours du temps, invalidant le modèle. Par conséquent, Predpol n’apparaît pas à ces acteurs plus pertinent qu’un algorithme basique se bornant à repérer les zones les plus criminogènes.