De l'économie à l'écologie, des priorités à soupeser
Cartographie du web
Grâce au logiciel Gargantext, nous avons pu faire des études statistiques sur les différents corpus de textes sur lesquels nous avons fait notre analyse. Nous avons pu par exemple observer la récurrence de certains mots ou expressions dans les articles, à la fois de presse et scientifiques.
Les mots-clés ont notamment été élevage, éleveurs, vaches, grande distribution, soja, végétariens, exploitations et viande. En analysant chronologiquement et statistiquement les textes du corpus, nous avons découvert en analysant la fréquence d’occurrence de certains mots une évolution du débat. Dans le cadre restreint mais essayant d’être aussi représentatif que possible de notre corpus, le terme « végétarien » qui apparaissait dans 10 % des articles en moyenne en 2010 se retrouve dans 45 % des articles sur l’élevage en 2015 : cela montre que cet enjeu a pris considérablement plus d’importance pour les médias, et donc est sans doute devenu un vrai sujet sociétal.
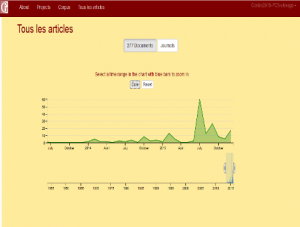
Répartition des articles sélectionnés au cours de l’année 2015 (notre corpus essaie d’être le plus complet possible vis-à-vis des thèmes abordés)
On voit clairement un pic en juillet 2015 : c’est très visiblement le moment où la controverse a eu le plus de retentissement. Essayons d’expliquer l’existence de ce « pic d’intérêt »pour l’élevage. Cette fois, une rapide analyse des articles présents dans notre corpus permet, selon nous, de comprendre ce phénomène. En effet, de nombreux articles de presse, parus par exemple dans Le Monde ou Ouest-France, font état d’une très forte agitation sociale autour de juin-juillet-août 2015. Les éleveurs manifestent beaucoup lors de cette période, et leurs nombreuses actions coup de poing (comme l’assaut de certaines grandes surfaces) attirent l’attention des grands médias français. Nous pouvons de plus supposer que l’importance de ce pic a été accrue par un effet « boule de neige » propre à la presse et aux médias de façon générale : de fait, si un grand quotidien (par exemple) publie un article sur un sujet sensible, cet article sera presque toujours suivi d’un autre article dans un autre quotidien, d’un reportage télévisé, et ainsi de suite. Cet effet est responsable d’une partie de l’augmentation du nombre de publications lors de crises telles que celle de juillet 2015. Nous avons aussi noté la forte présence de quotidiens régionaux : Ouest-France arrive en première place avec 18% des articles. Cela peut s’expliquer par le fait que ce sont beaucoup les riverains des régions les plus agricoles qui ont vu et se sont le plus interrogés sur la colère des éleveurs. On peut aussi relever l’existence de deux dates importantes, toutes deux situées autour du mois de juillet 2015 :
• 17 juin : Après un débat autour de Stéphane le Foll – alors ministre de l’agriculture – la filière bovine s’engage à relever le prix de la viande payé aux éleveurs.
• 22 juillet : Annonce par le gouvernement d’un « plan d’urgence » afin de répondre à la crise touchant les éleveurs. Ce plan inclut plus particulièrement 24 mesures, comme « la mobilisation des abatteurs transformateurs, industriels laitiers et acheteurs de la grande distribution pour respecter la hausse de prix à laquelle ils se sont engagés », ainsi que le déblocage de 600 millions d’euros d’aides.
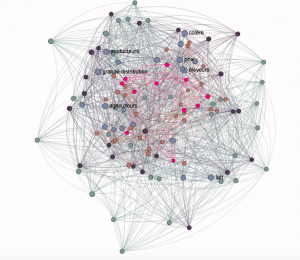
Nous avons aussi pu observer le nombre de connexions de différentes expressions entre elles. Ces connexions sont ensuite schématisées par un cluster (ici très général représentant tous les termes repérés par le logiciel parmi 45 documents). Le cluster suivant, lui, a été réalisé en sélectionnant parmi un corpus de 50 documents tous les mots traitant de la crise du lait, comme colère, marge, lait, quotas laitiers, Etat. On voit sur cette image apparaître les mots les plus souvent présents dans les articles et leurs relations avec les autres documents.
Cluster correspondant aux termes concernant la crise des éleveurs de vaches laitières parmi un cluster de 50 documents
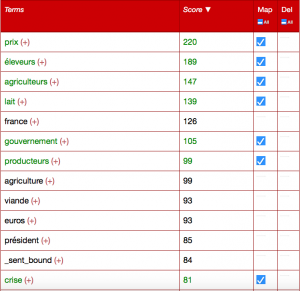
Voici de plus un extrait des termes sélectionnés pour former ce cluster particulier, avec en vert les termes étudiés et en noir les autres termes repérés par le logiciel :
Extrait de la liste des termes sélectionnés pour faire le cluster (en vert)
Nous avons créé aussi un corpus scientifique en interrogeant CAIRN, Scopus et Business Source Elite pour le constituer, à l’aide de mots comme breeding, cattle, genetics et farming, avec une limite de temps de 5 ans. Cette fois, nous avons regardé les publications au niveau international. Les articles traitaient beaucoup de nouvelles méthodes génétiques accroissant les performances (surtout en interrogeant Scoups). Les principaux articles qui nous ont intéressé et que nous avons lu sont présents dans la bibliographie.