Les modèles utilisés pour obtenir les valeurs des différents indicateurs d’impacts (prévus ou réels) diffère de manière importante entre les études ex et post-ante.
Études ex-ante:
Le nombre de modèles développés pour les études ex-ante est impressionnant. Il serait impossible de lister toutes les méthodes utilisées et toutes leurs variantes. Nous nous intéresserons donc plutôt aux grands types de modèles, qui sont les plus utilisés, selon les spécialistes du domaine.
1- Patrice Bouvet explique…
Patrice Bouvet explique qu’un des types de modèles massivement utilisé pour la prévision grossière d’impacts repose sur le principe de multiplication (théorie développé par J. M. Keynes): l’organisation d’un grand évènement sportif nécessite de nombreuses dépenses pouvant être considérées comme une injection de revenu supplémentaire pouvant conduire à la création d’emplois, ces dépenses venant s’ajouter aux dépenses courantes effectuées sur le territoire considéré. Cet investissement supplémentaire induit une demande supplémentaire, qui entraîne des revenus supplémentaires, qui eux-mêmes réinvestis vont induire de nouveau de la demande et ainsi de suite.
Le coefficient d’induction (noté i), qui est le rapport entre les revenus additionnels engendrés et l’investissement consenti, est la variable la plus importante du modèle.
Le premier cycle d’investissement engendre i*R (R étant le l’investissement initial).
En supposant que tous le revenu engendré est réinvesti, le second cycle engendre i2*R, et ainsi de suite…
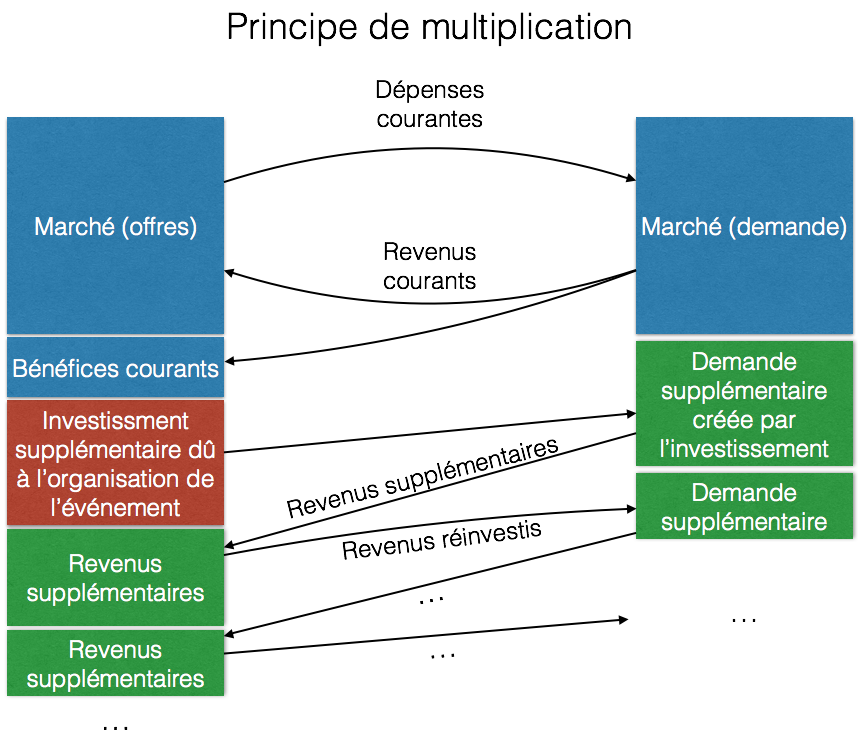
Le principe de multiplication est extrêmement pratique, car il peut s’appliquer à tous les domaines de l’économie auxquels on s’intéresse. De plus, il suffit de déterminer i pour obtenir l’impact, ce qui simplifie considérablement la tâche des analystes. Le coefficient d’induction est déterminé par analyse de données historiques, soit sur le pays organisateur, concernant une mesure semblable, soit sur d’anciens pays organisateurs.
Bien que très utilisé, et défendu par de nombreux économistes, tels que Barde, ou plus récemment Dinnie, ce modèle est très contesté. Par exemple, selon Porter:
« Investigator bias, data measurement error, changing production relationships, diminishing returns to both scale and variable inputs, and capacity constraints anywhere along the chain of sales relations lead to lower multipliers. Crowding out and price increases by input suppliers in response to higher levels of demand and the tendency of suppliers to lower prices to stimulate sales when demand is weak lead to overestimates of net new sales due to the event. These characteristics alone would suggest that the estimated impact of the mega-sporting event will be lower than the impact analysis predicts. »
2- Leontief, économiste historique, a développé un type de modèle…
Leontief, économiste historique, a développé un type de modèle qui est également souvent utilisé pour la prévision des impacts économiques des grands événements sportifs. Il s’agit des modèles Input-Output (I-O). Le principe de ce type de modèle est que l’évolution de chaque secteur de l’économie (son chiffre d’affaires en t+dt) dépend du chiffre d’affaire en t de tous les secteurs de l’économie (avec des coefficients variables), de l’importation de produits dans ce secteur, et de la demande pour le secteur. L’organisation de l’événement sportif est alors modélisé par une augmentation de la demande à un temps t0, qui entraîne ensuite une variation du chiffre d’affaire des différents secteurs de l’économie par la suite.
Les modèles I-O sont très peu contestés en eux-mêmes mais ils font appels à des hypothèses et d’autres modèles pour prédire la demande, ce qui peut engendrer de grosses erreurs à long terme, selon Tracy Taylor.
Études post-ante:
 Fondamentalement, une étude post-ante n’a pas besoin de modèle, mais juste d’analyser les données recueillies, avant, pendant et après l’événement. Cependant, dans la plupart, pour ne pas dire tous les cas, comme le précisent Li & Blake, de nombreuses données sont manquantes ou insuffisantes. C’est pourquoi les économistes réalisant des études post-ante font souvent appel à des modèles de prévision des données qui leur manque à partir d’autres données, auxquelles ils ont cette fois pu avoir accès. Ces modèles sont généralement, comme le précisent toujours Li & Blake, des régressions (ou CGE, pour computable general equilibrum), pas forcément linéaires.
Fondamentalement, une étude post-ante n’a pas besoin de modèle, mais juste d’analyser les données recueillies, avant, pendant et après l’événement. Cependant, dans la plupart, pour ne pas dire tous les cas, comme le précisent Li & Blake, de nombreuses données sont manquantes ou insuffisantes. C’est pourquoi les économistes réalisant des études post-ante font souvent appel à des modèles de prévision des données qui leur manque à partir d’autres données, auxquelles ils ont cette fois pu avoir accès. Ces modèles sont généralement, comme le précisent toujours Li & Blake, des régressions (ou CGE, pour computable general equilibrum), pas forcément linéaires.
Comme ce travail est très long, comme vu dans la rubrique Données, les études post-ante se focalisent généralement sur un ou, au mieux, quelques impacts, engendrés par la variation d’un unique paramètre.
